§ 01 · 2026
Euler's Formula in its Full Elegance
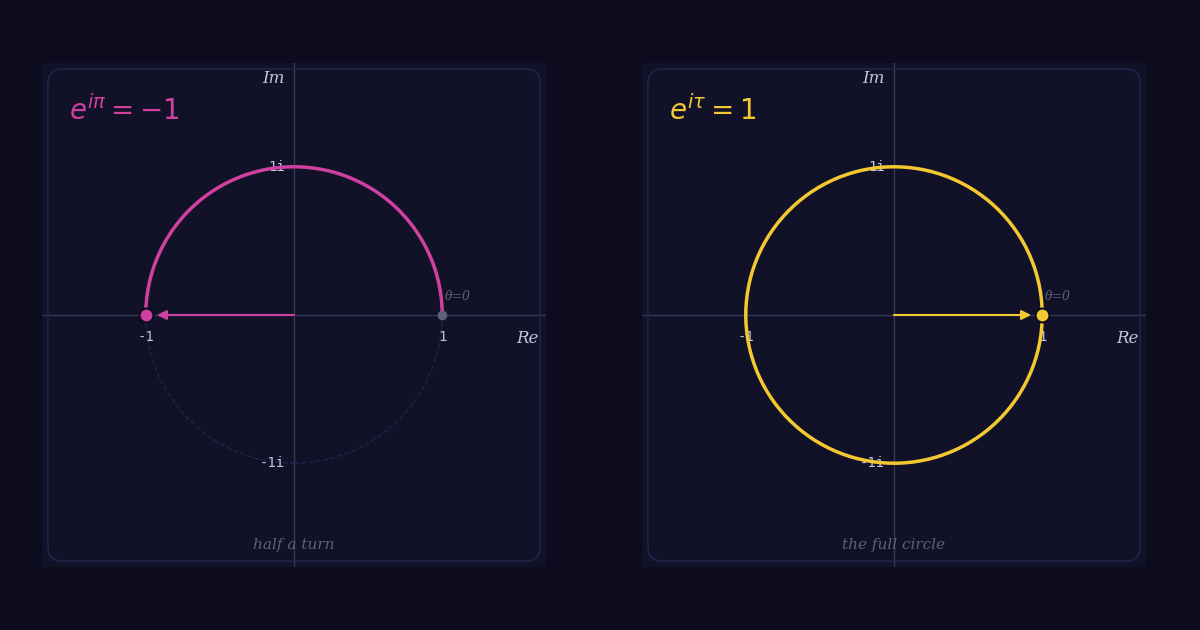
Why eiπ + 1 = 0 is not the most elegant equation — and eiτ = 1 is
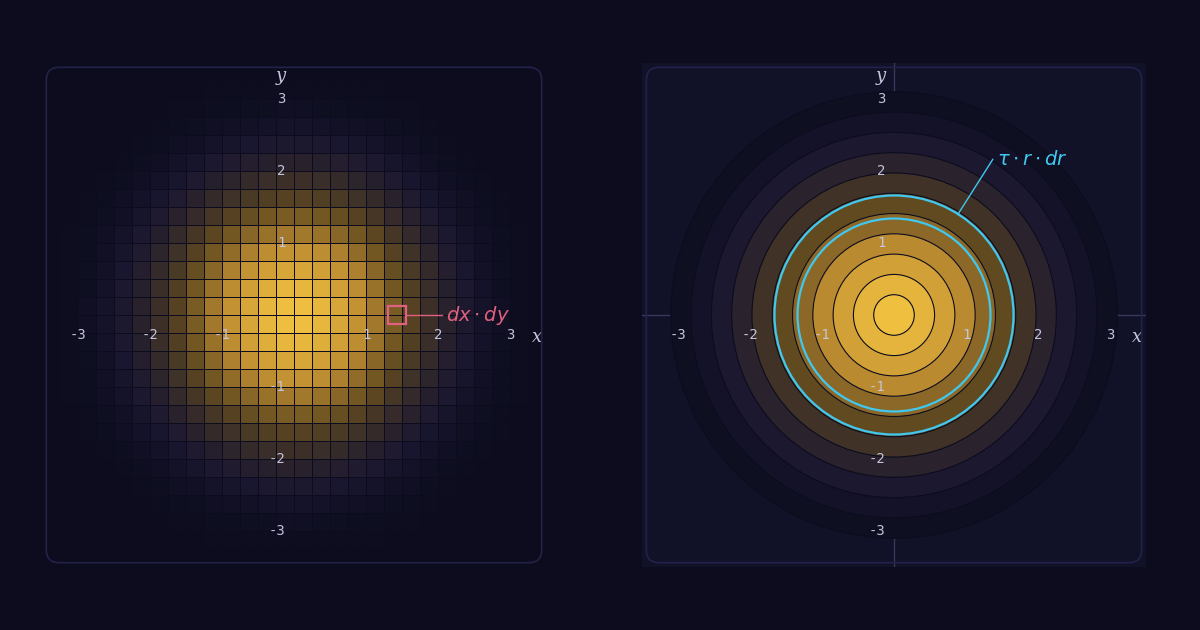
Interactively derive eiθ = cos θ + i sin θ from the fold-and-add method. See the unit circle emerge from the series, and why the famous identity is just a half-frame of the full story.
Read in English → 阅读中文版